5.4.1. Реляционные базы данных
Все реляционные базы данных используют в качестве модели хранения данных двумерные таблицы. Эта модель выбрана потому что она в основном знакома всем пользователям и рассматривается как "естественный" путь представления данных. Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или "отношений" в терминологии СУРБД) с некоторой избыточностью. Избыточность контролируется путем приведения отношений к канонической "нормальной" форме, которая минимизирует ненужную избыточность без уменьшения связей между элементами данных.
- Каждое отношение (таблица) может быть представлено в виде прямоугольного массива со следующими свойствами:
- Каждая ячейка в таблице представляет точно один элемент данных; нет повторяющихся групп.
- Каждая таблица имеет однородные столбцы; все элементы в любом из столбцов одного и того же вида.
- Каждому столбцу назначено определенное имя.
- Все строки различны; дублировать строки не разрешается.
- И строки, и столбцы не зависят от последовательности; просмотр в различной последовательности не может изменить информационное содержание отношения.
Каждая строка олицетворяет уникальный элемент данных, который ею и описывается.
Столбцы представляют собой отдельные куски информации (атрибуты данных), которые известны о данном элементе. Строки обычно называют записями, а столбцы - полями.
Кроме того, для обработки отношений разрешены только следующие операции:
- Добавить и Удалить запись. (Редактирование косвенно разрешено в виде конкатенации операций "Добавить" и "Удалить")
- Соединение (при котором временное отношение создается путем соединения информации двух отношений, используя общие поля).
- Выборка (в которой выбирается подмножество записей в отношении, основываясь на определенных значениях или ряде значений в выбранных полях).
Другие операции с данными обычно не поддерживаются в базах с реляционной структурой. Добавление произвольных данных, которые, например, не соответствуют ни одному полю в описании данных, запрещено. Добавление поля для произвольных данных потребовало бы перестройки (реструктурирования) базы данных. А этот, зачастую очень длительный, процесс может выполняться только когда базой данных никто не пользуется.
Вообще, лишь немногие реальные базы данных могут быть описаны при помощи единственной таблицы. Большинство приложений используют множество таблиц, которые содержат столбцы (поля) с одинаковым именем. Эти общие данные позволяют объединяя две (или несколько) таблицы, строить осмысленные ассоциации. Лучше всего это иллюстрируется примером. Рассмотрим два отношения "Служащий" и "Отдел", показанные на рис.5.14.
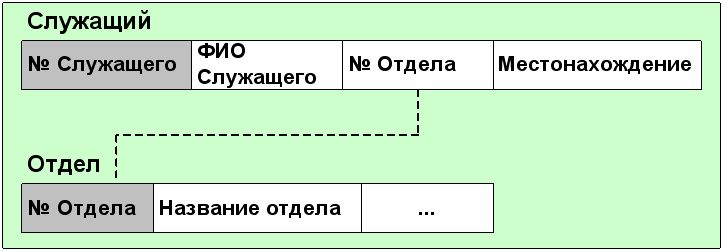
Рис. 5.14. Отношения "Служащий" и "Отдел".
В этом примере поля Номер Служащего и Номер Отдела выделены; это указывает на то, что эти поля - первичные ключи. Это означает, что элементы данных в этих полях единственным образом определяют запись (т.е. никакие две записи не имеют одинакового элемента данных в ключевом поле). Более того, поле N отдела обнаруживается в обеих таблицах. Это позволяет объединить две таблицы таким образом, чтобы, например, определять Название отдела для любого заданного Служащего.
Во многих случаях это объединение не такое простое. Предположим, нам требуется найти способ для определения, кто является Руководителем для любого Служащего. Мы могли бы создать следующую структуру данных (рис.5.15).
Эта на вид интуитивная структура может вызвать проблемы из-за избыточности связи отношения "Руководитель", связанного с отношением "Служащий" как напрямую, так и через отношение "Отдел". Эта избыточность позволяет руководителю служащего отличаться от руководителя отдела служащего. Если это не разрешено, то приведенная структура таблиц не подходит.
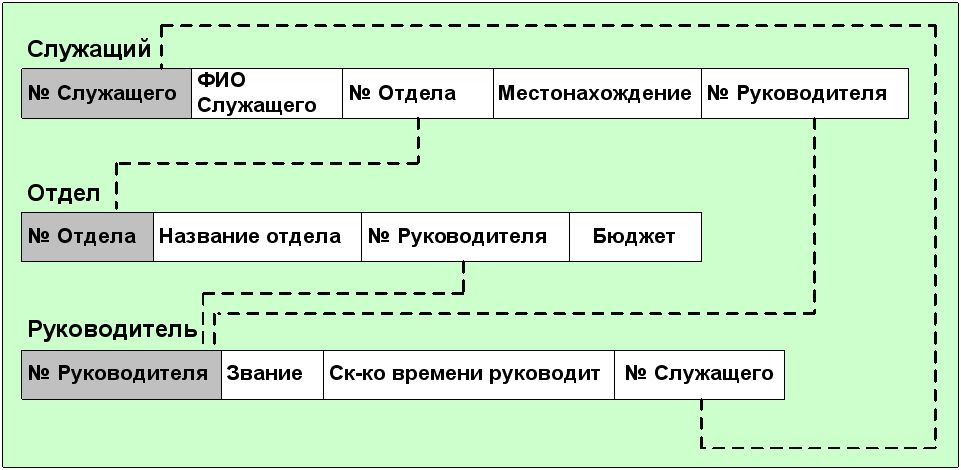
Рис. 5.15. Отношения «Служащий», «Отдел» и «Руководитель».
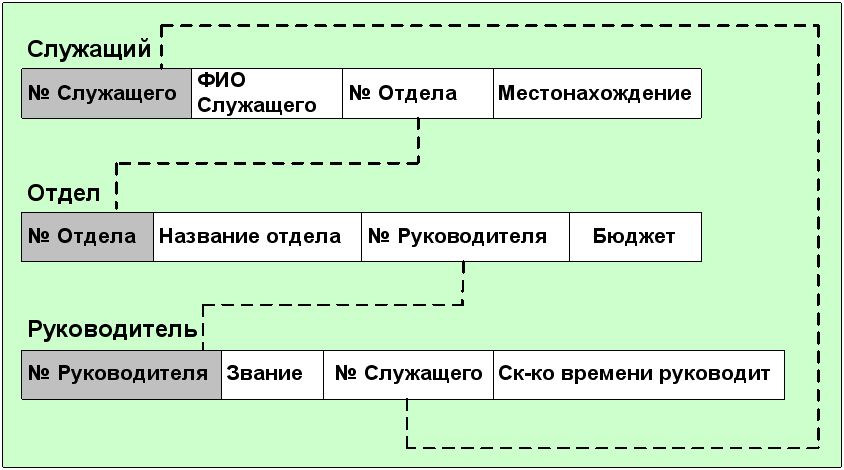
Рис. 5.16.
Вместо нее более подходящей была бы структура, представленная на рис.5.16.
Эта структура удаляет избыточность, которая позволяет Служащему иметь Руководителя, отличного от Руководителя его Отдела. Но делая это, она удаляет прямую связь, которая может быть желательна с точки зрения производительности больших баз данных. Эта взаимосвязь между производительностью и целостностью данных присутствует фактически во всех моделях баз данных.
Простой реальный пример может потребовать еще более сложной структуры.
Пусть Служащий является членом более чем одного Отдела. Правила соединения в реляционных базах данных не разрешают связей "многие-ко-многим" (которые можно обозначить при помощи стрелки с двойным указателем на каждом конце). Чтобы представить отношение с такими связями (например, каждый Отдел имеет многочисленных Служащих и каждый Служащий может быть членом Многочисленных Отделов), нам надо создать отдельное отношение, которое является гибридом двух столбцов (рис.5.17):
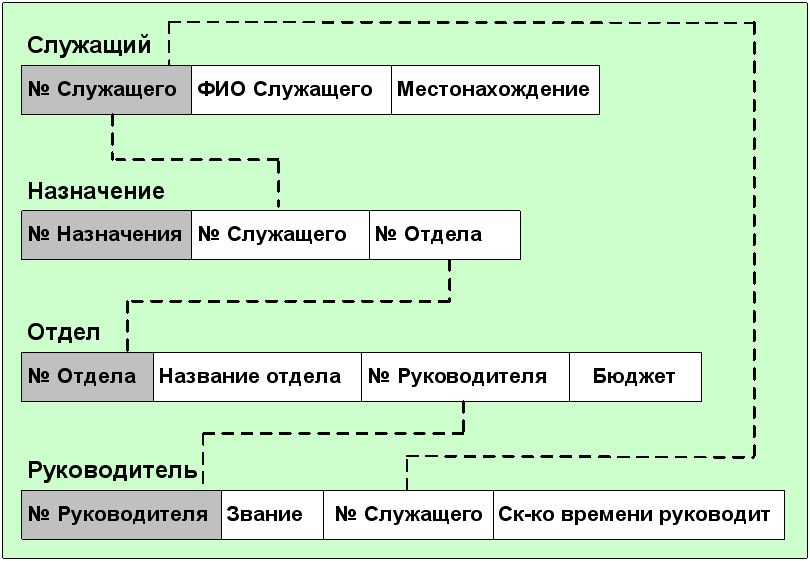
Рис. 5.17. Отношения «Служащий», «Назначение»,
«Отдел» и «Руководитель».
Здесь отношение "Назначение" содержит запись для каждого отдела, сотрудником которого является служащий. То есть, если Служащий работает в Отделе, то соответствующие Номер Служащего и Номер отдела обнаруживаются точно в одной записи отношения "Назначение". Поле Номер Назначения фактически не нужно, так как Номер Служащего и Номер Отдела могут вместе служить ключем. В большинстве (но не во всех) СУРБД разрешены отношения с составными ключами. Для тех из них, в которых ключ должен быть представлен обязательно одним полем, структура будет такой, как представлена выше.
"Естественный подход" с использованием таблиц может оказаться еще более "притянутым за уши", когда данные - разреженные. Разреженные данные означают, что не каждое поле в каждой записи содержит данные. В некоторых приложениях данные очень разреженные - только несколько из большого числа столбцов, определенных для данного отношения, могут содержать данные в каком-либо заданном ряду. Если в реальном приложении типично, что данные разреженные, то обычно пользователь не рассматривает их как табличные. Например, представим отношение, описывающее посещение пациентом врача. Оно может иметь поля, которые содержат результаты обследования: радиограмма, ультразвук, температура, вес и т.д. Большинство из этих полей может быть пусто для какого-либо пациента. Представить их в качестве полей таблицы в лучшем случае противоестественно. Более естественно представить эти данные в виде списка элементов, чем в качестве полей таблицы. Воплотить в жизнь эту точку зрения пользователя в реляционной базе данных нелегко. Эти различные элементы нельзя занести в одну таблицу, так как они нарушают однородность столбца - данные, хранящиеся в полях, не все одного типа, как это требуется в реляционных таблицах.
Реляционные базы данных были бы совсем непригодны, если бы эти разреженные данные действительно хранились внутри прямоугольного массива, так как для этих пустых элементов данных надо было бы выделять пространство. В действительности, большинство современных СУРБД используют таблицы как "логические" структуры, но в качестве внутренних "физических" структур используют структуры, которые могут хранить редкие данные более эффективным способом, таким как В-дерево. Выбор физической структуры иногда предоставляется разработчику БД как возможность оптимизации производительности.